Unifying Driver Check-In Support
Background
Amazon Flex drivers are independent contractors who pick up delivery blocks — scheduled time slots where they pick up and deliver packages. When something goes wrong at check-in, they call support. And when they called support, they were reaching a customer service associate (CSA) who had to navigate six different tools just to begin helping them.
The fragmentation wasn't just inconvenient. It was expensive — for drivers who lost pay and reliability standing, for CSAs who couldn't do their jobs efficiently, and for Amazon at scale.
I was brought in as the sole designer to unify the experience into a single, intelligent workflow.
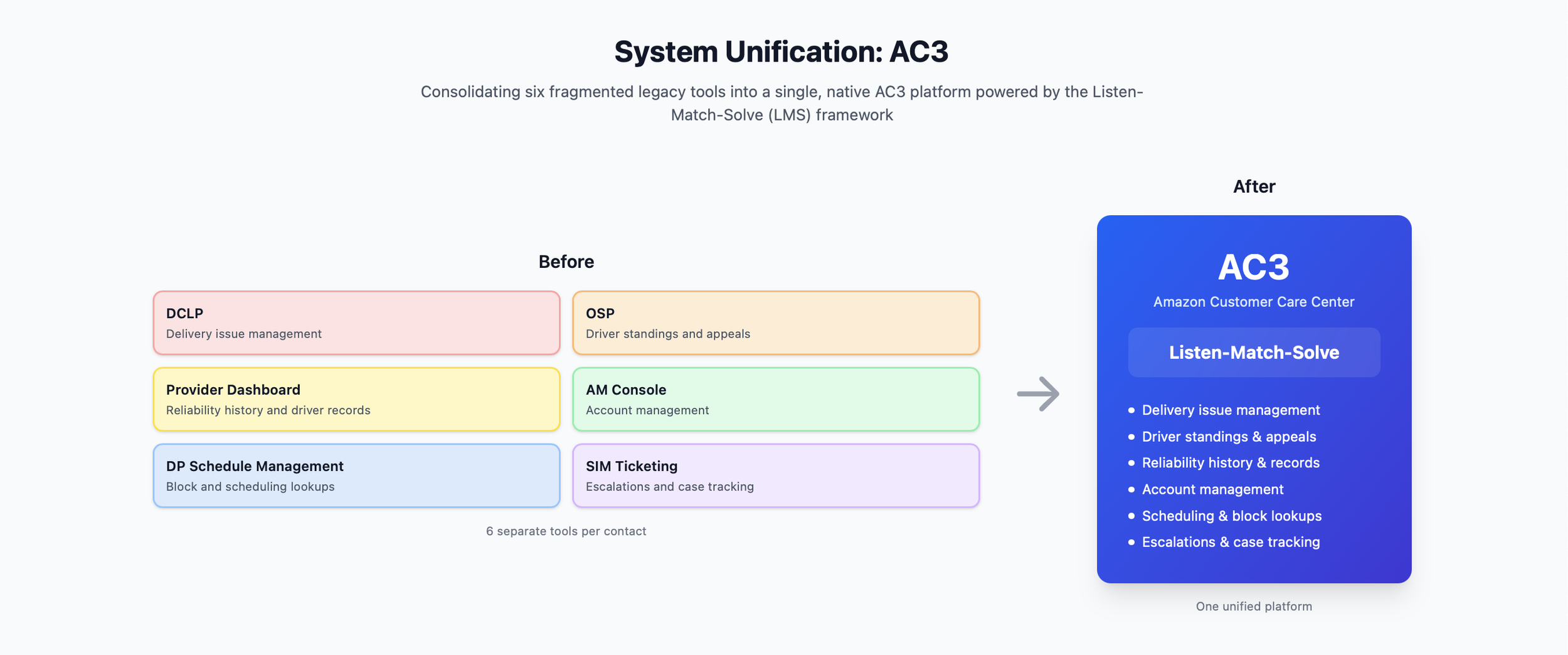
AC3 (Amazon Customer Care Center) is Amazon's internal contact center platform where CSAs handle driver support contacts via phone, chat, and email. It uses a design system called Listen-Match-Solve (LMS) — guiding CSAs through identifying and resolving driver issues in a structured, consistent way. The legacy tools were never natively built inside AC3 — they were bolted on from older systems, which is what made the fragmentation so costly.
Before this project, resolving a single check-in contact meant a CSA had to navigate up to six separate tools — none of which were native to AC3 or designed to work together.
DCLP — delivery issue management
OSP — driver standings and appeals
Provider Dashboard — reliability history and driver records
AM Console — account management
DP Schedule Management — block and scheduling lookups
SIM Ticketing — escalations and case tracking
The Problem
Working alongside two senior PMs and a principal engineer, my charge was clear — redesign the check-in support experience inside AC3 so CSAs could resolve driver issues faster, more accurately, and more completely. The baseline data made the urgency hard to ignore.
Average handle time was 42% above target
Policy compliance sat at just 76% — against a 95% goal
31% of contacts were repeats — drivers calling back because their issue wasn't resolved the first time
The targets were equally clear: reduce handle time by 30%, bring compliance above 95%, and cut repeat contacts by 40%. But before any of that could happen, we needed to understand why things had gotten this bad in the first place.
Research
As a team we went directly to the source. That included an on-site visit to Huntington, West Virginia where we interviewed and observed CSAs in their actual work environment — watching in real time how they moved between tools, managed live calls, and made decisions under pressure. Alongside that, we conducted:
45 CSA shadowing sessions across 8 global marketplaces
28 interviews with operations leaders
12 driver focus groups
Analysis of 500 contact transcripts and 2.3M driver contacts over six months
Two distinct CSA profiles emerged. Experienced associates knew the policies but were forced to improvise across tools — accumulating cognitive load on every call. Newer associates lacked the institutional knowledge to compensate, leading to policy errors that directly affected drivers' pay and reliability scores.
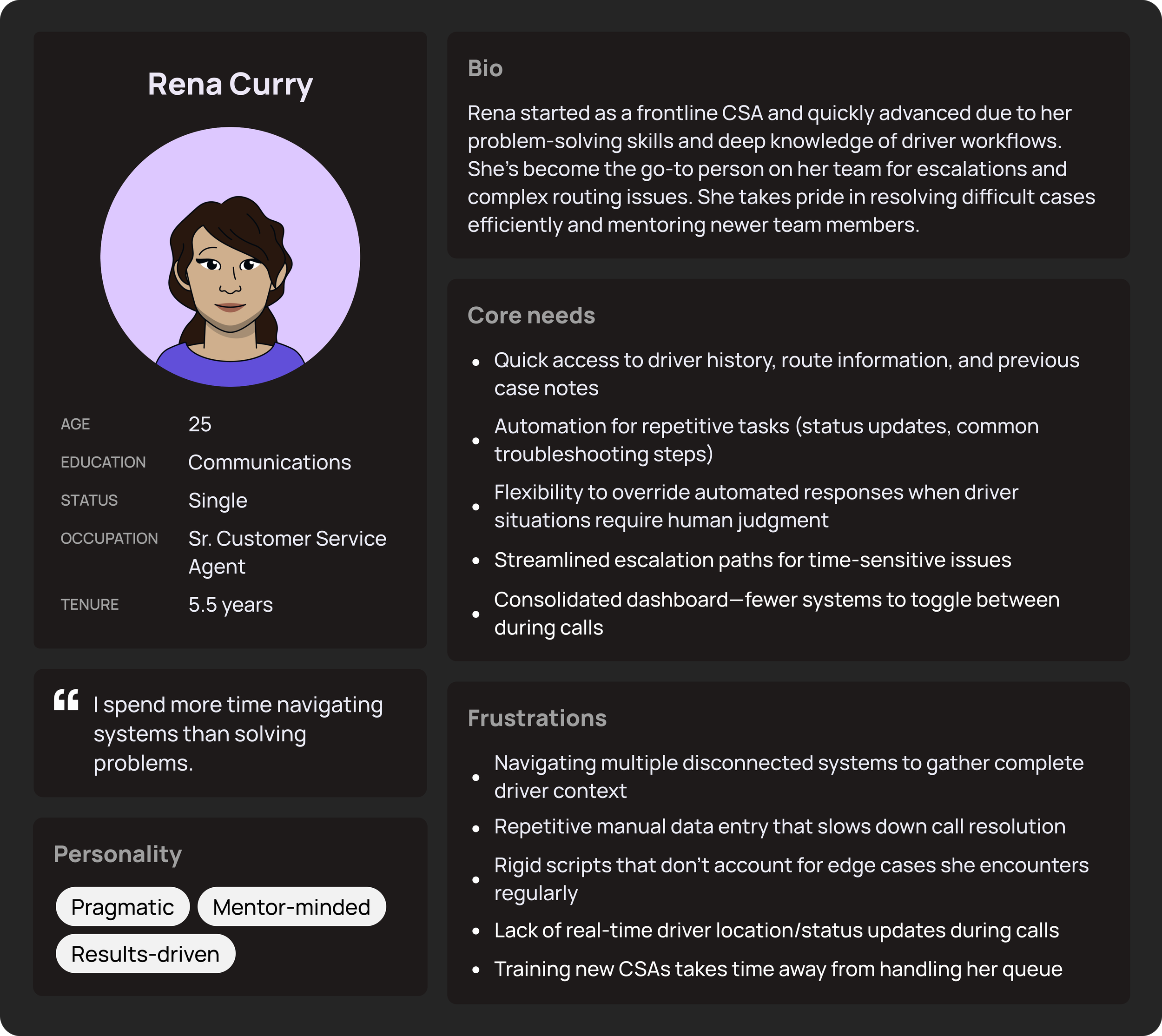
Senior Customer Service Associate (Driver Support)
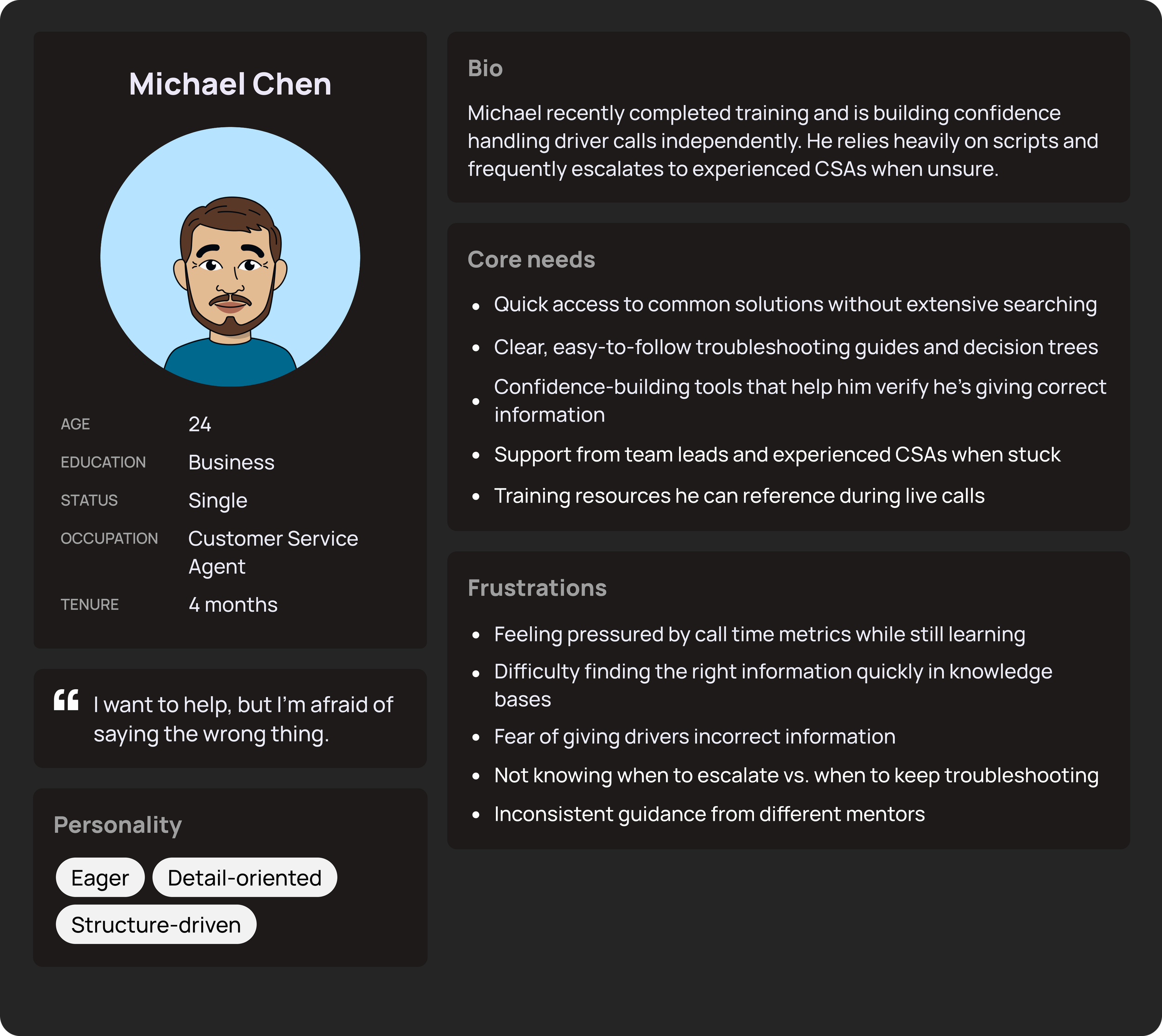
New Customer Service Agent
The root cause wasn't a people problem. It was a systems problem. And that distinction shaped every design decision that followed.
Navigating the Complexity
Check-in policy is genuinely intricate — and getting alignment on how to design for it was one of the hardest parts of the project. The workflow had to intelligently respond to a matrix of conditions — driver timing, location, issue type, business type, and marketplace — each with its own rules and thresholds.
| Scenario | Timing Window | Location Required | CSA Action |
|---|---|---|---|
| Too early | > 15 min before block start | At station | Ask driver to return closer to block start time |
| On time / early | < 15 min before block start | At station | Proceed with check-in assistance |
| Late — within threshold | US: ≤ 5 min / UK, IN, JP, SG: ≤ 8 min | At station | Proceed with check-in assistance |
| Late — past threshold | US: > 5 min / UK, IN, JP, SG: > 8 min | At station | Cannot check in — offer reliability appeal |
| Not at station | Any | Not at station | Driver must be on-site to check in |
| Previous block packages | < 15 min before block start | At station | Resolve outstanding packages first |
| License scan issue | < 15 min before block start | At station | Guide driver through scan or escalate |
| Selfie verification issue | ≤ 5 min after block start | At station | Override if eligible by marketplace |
| Check-in override — AMZL | < 15 min before block start | At station | Defer to station staff |
| Check-in override — Grocery | < 15 min before block start | At station | Override if eligible by marketplace |
I led collaborative design workshops with process engineers, program teams, PMs, and engineering throughout — using a double diamond approach to diverge on possible solutions, pressure-test them against policy requirements, business goals, and dev capacity, and converge on what was actually buildable.
It was rarely linear. New questions surfaced constantly. Competing priorities created real tension — policy compliance, business flexibility, and engineering bandwidth didn't always point in the same direction. Leaning into Amazon's Bias for Action, I kept moving forward — proposing solutions, getting feedback, failing fast, and refining incrementally until we landed on something everyone could build toward.
Throughout, I worked closely with the Amazon Flex app designer to ensure the CSA-facing workflow felt like a natural extension of what drivers had already experienced in the app.
What I Designed
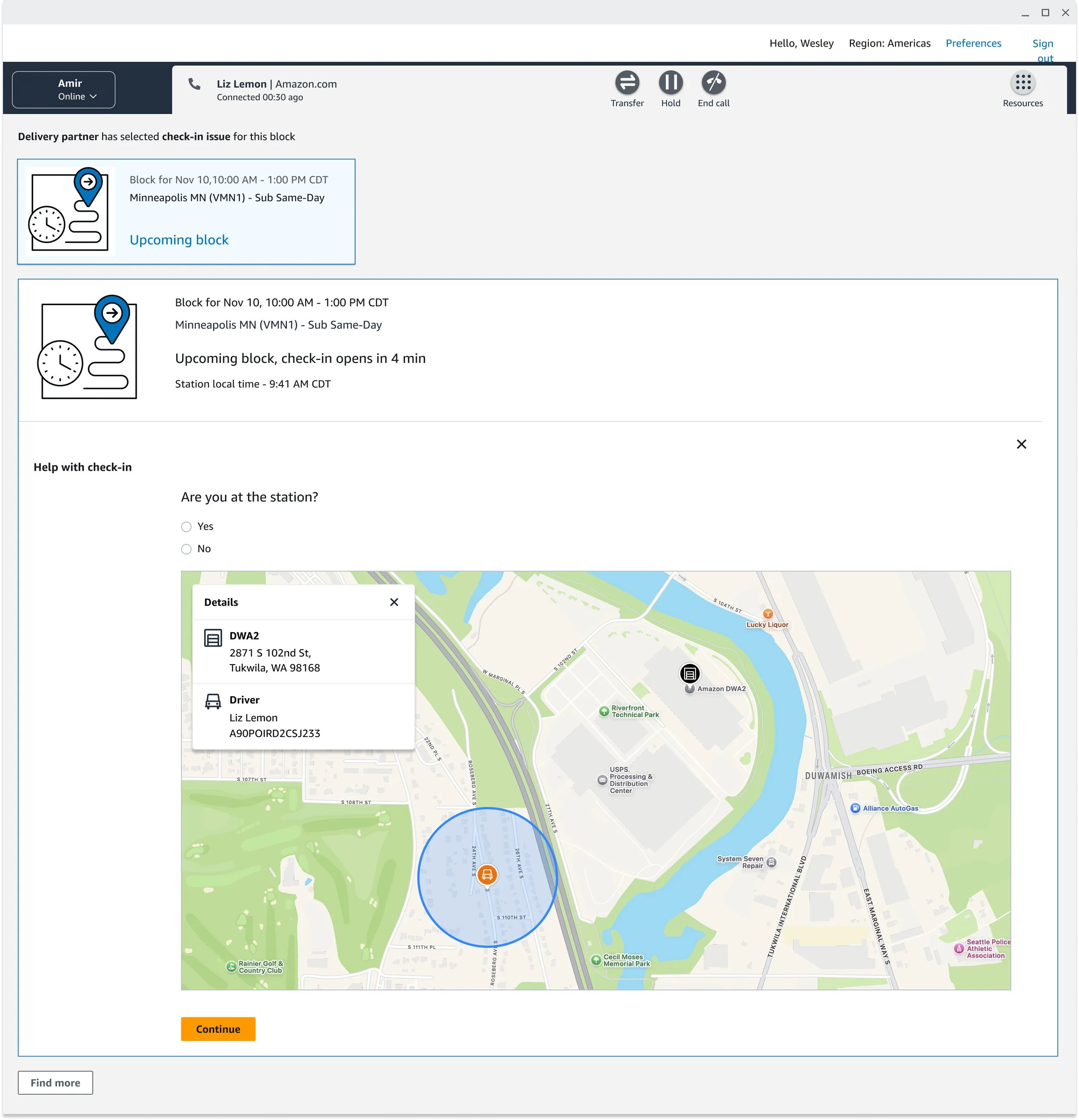
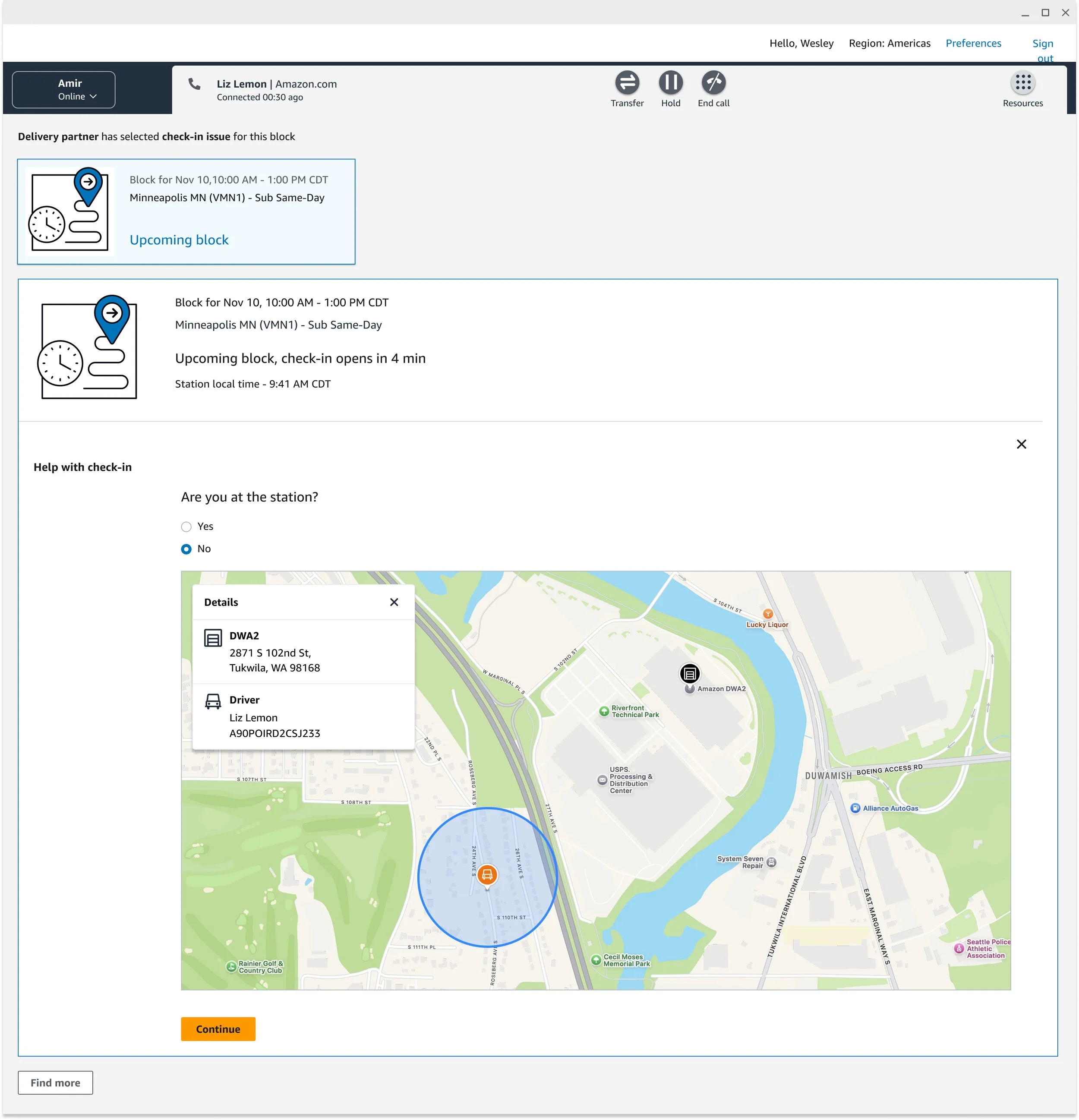
After weeks of iteration and alignment, what research and collaboration made clear was that CSAs didn't need more information — they needed the right information at the right moment. The solution was a guided workflow inside AC3 built around three principles.
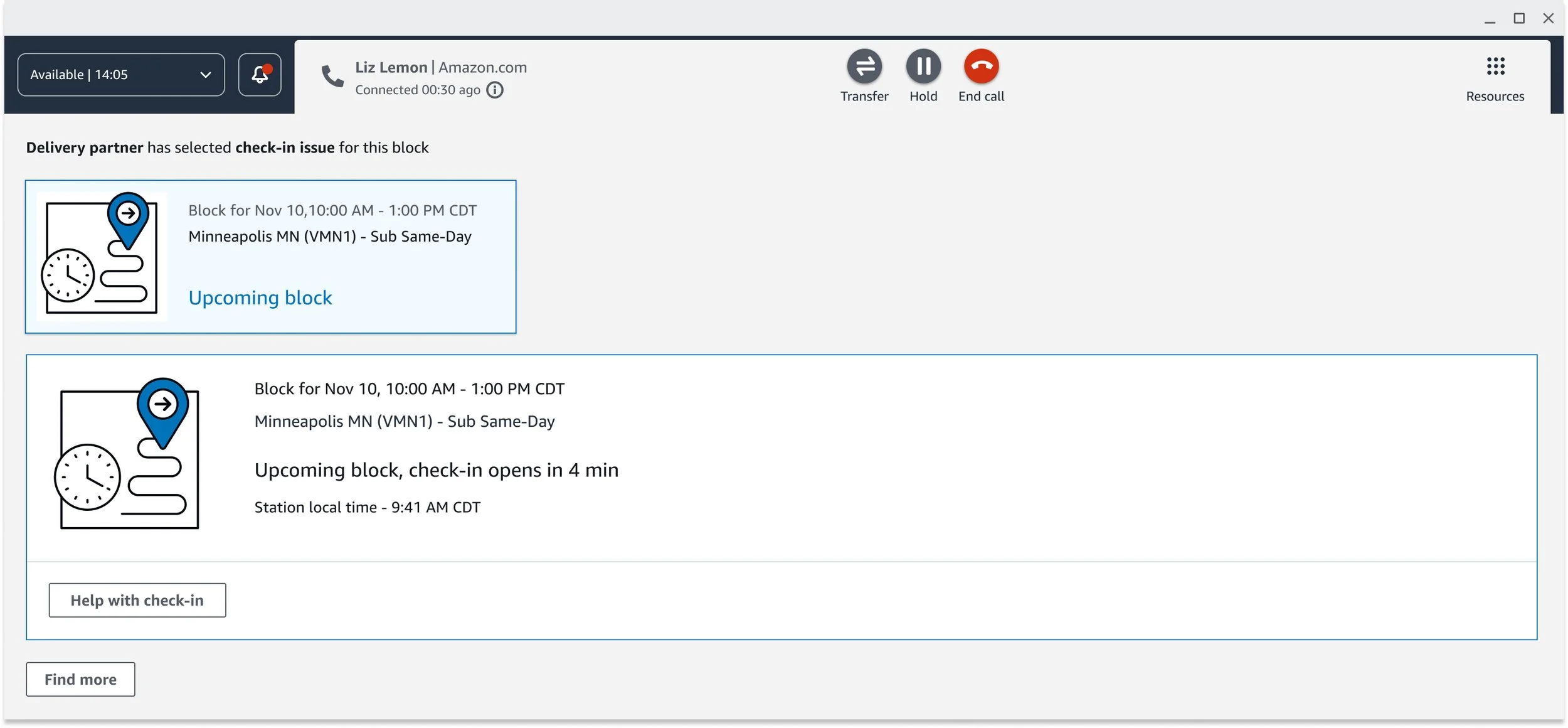
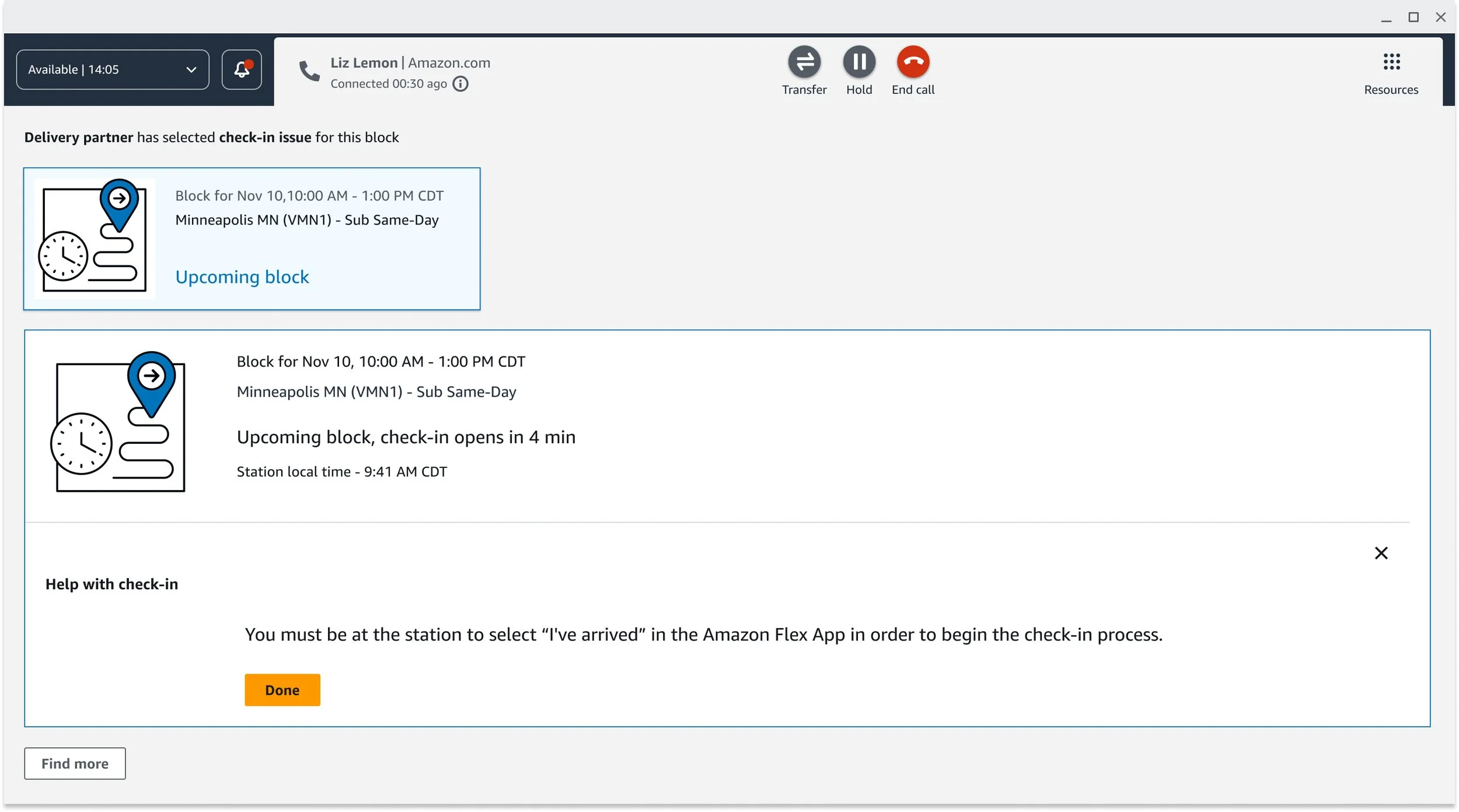
Make the policy invisible. Rather than surfacing documentation and trusting CSAs to interpret it, the workflow does the interpretation. It checks local time at the block location, the driver's geolocation, business type, and marketplace-specific rules — then tells the CSA exactly what to do next. If the driver is past the check-in window, that option disappears. If they're within it, the appropriate override options appear based on their specific situation and marketplace.
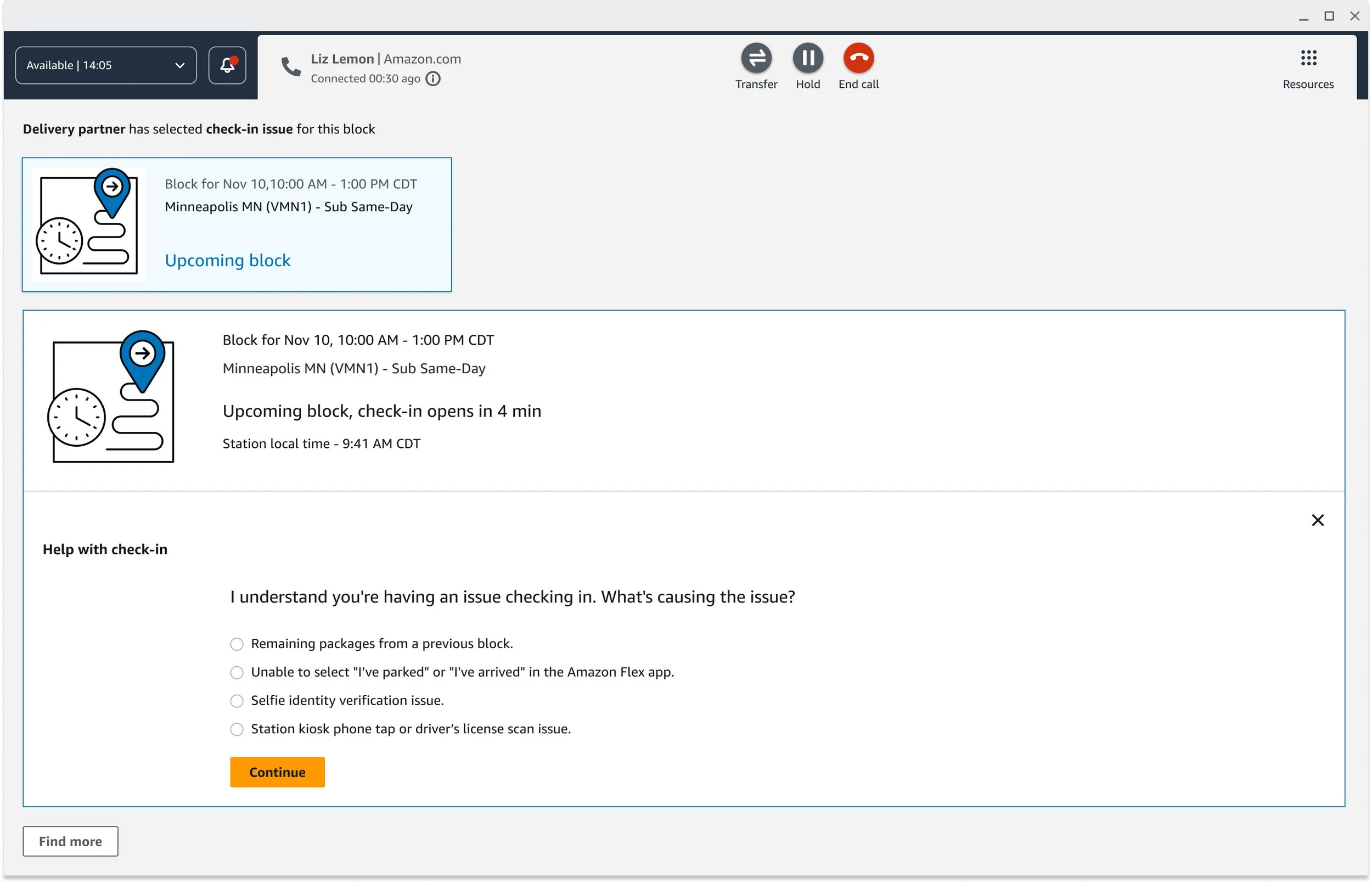
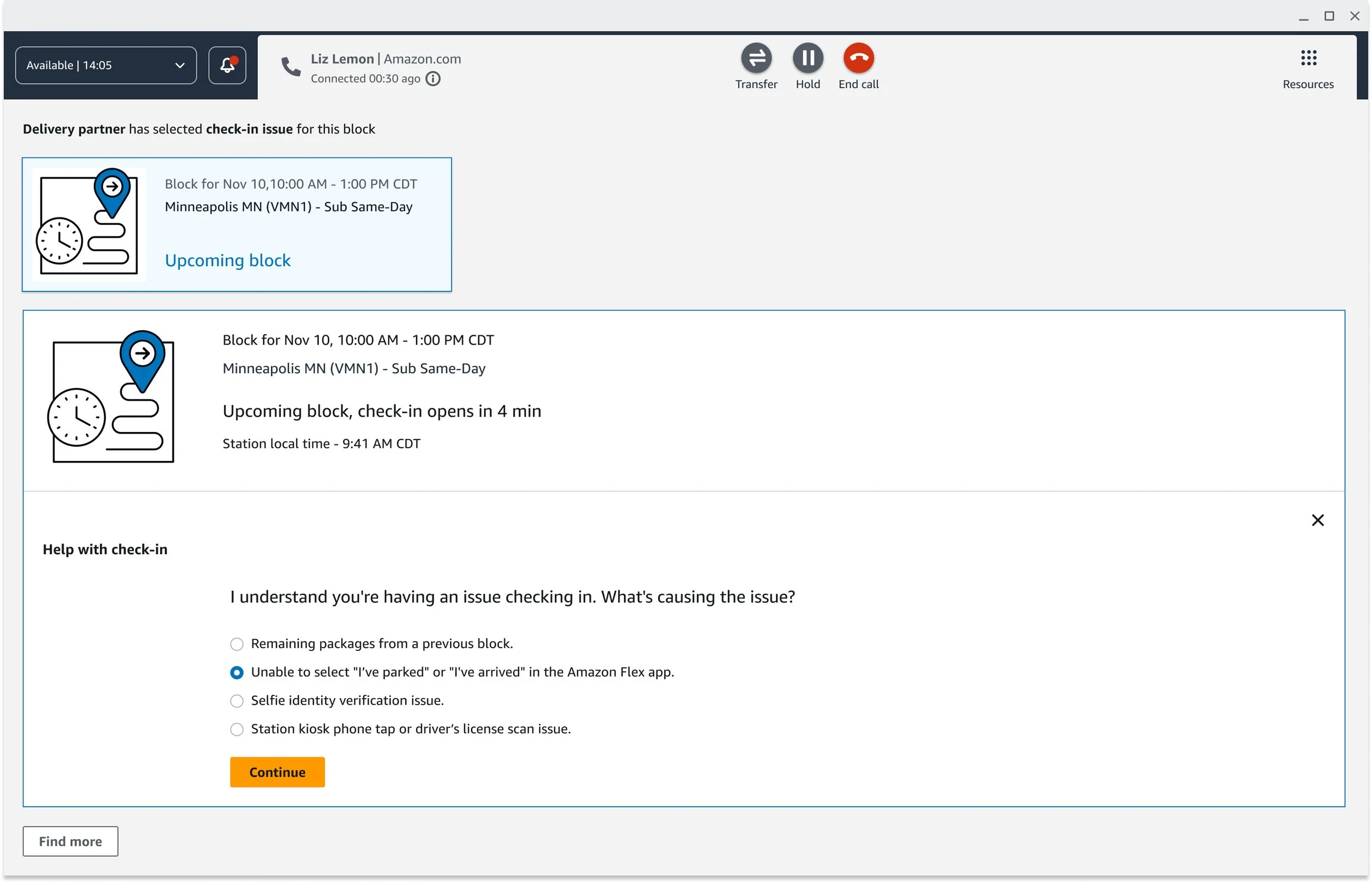
Show only what's relevant. Check-in contacts can branch in many directions — license scan issues, packages from a previous block, selfie verification failures, late forfeitures. I applied progressive disclosure throughout, so CSAs saw only what was relevant to their current decision point. This reduced cognitive load without hiding information they might need downstream.
Resolve both issues in one contact. This was the most significant design decision of the project. When check-in can't be completed and the driver's block is now at risk, the workflow transitions directly into a reliability appeal — without the driver hanging up and calling back. One contact. Both issues resolved. It was the first time these two workflows had ever been connected at Amazon, and it required close alignment across product, process engineering, and program teams to make it happen.
Results
Every target was met or exceeded. But the repeat contact reduction is the number that matters most to me — because behind every callback is a driver who didn't get help the first time. Cutting that by nearly half meant real people getting back to work faster, and CSAs who could focus on the next person who needed them.
| Metric | Before | After |
|---|---|---|
| Avg. Handle Time | Baseline | ↓ 35% |
| Policy Compliance | 76% | 94% |
| Repeat Contacts | 31% | ↓ 45% |
| CSAT | 3.2 / 5 | 4.2 / 5 |
| Annual Cost Savings | — | $12M |
What It Unlocked
The fragmentation that once defined driver support at Amazon now has a clear path forward. The workflow patterns, policy logic, and component structure built here are being extended across package management, standings appeals, and pre-departure support — covering an estimated 70% of all driver contact volume across eight global marketplaces by end of 2025. What started as a check-in problem became the foundation for how Amazon supports every driver, on every contact.